

Defensibility: Stacks
Part 2: Technology markets are organized around “stacks”

This is the second in a series of posts dedicated to understanding defensibility in technology-driven markets.
If you’re new, start with the first post and subscribe to be notified as new posts are published.
To identify business opportunities in technology-driven markets, we must predict how players interact both technically and financially. Enter “the stack”, a visualization showing how individual components relate to each other. Typically:
User interfaces and external APIs are on the “top of the stack”
Physical machines and cloud infrastructure providers are on the “bottom of the stack”.
In the middle are components that enable applications to function (e.g., internal “middleware” services, databases, file storage, deployment tools, development tools, and security tools).
When building a product, vendors assemble a unique stack by combining components built in-house or sourced externally. In each case they make “build vs. buy decisions”. Sometimes end-customers add a few things to a vendor’s stack themselves, such as when enterprises implement security and compliance tools or deploy software in their own environments.
To analyze complex technology ecosystems using stacks, we’ll cover several topics:
Stacks exist because people make “build vs. buy” decisions.
While each is unique, stacks tend to cluster based on use case and customer type.
Subtle requirements create “leaky abstractions” in stacks.
These principles, while universal, apply in the case of the current AI market.
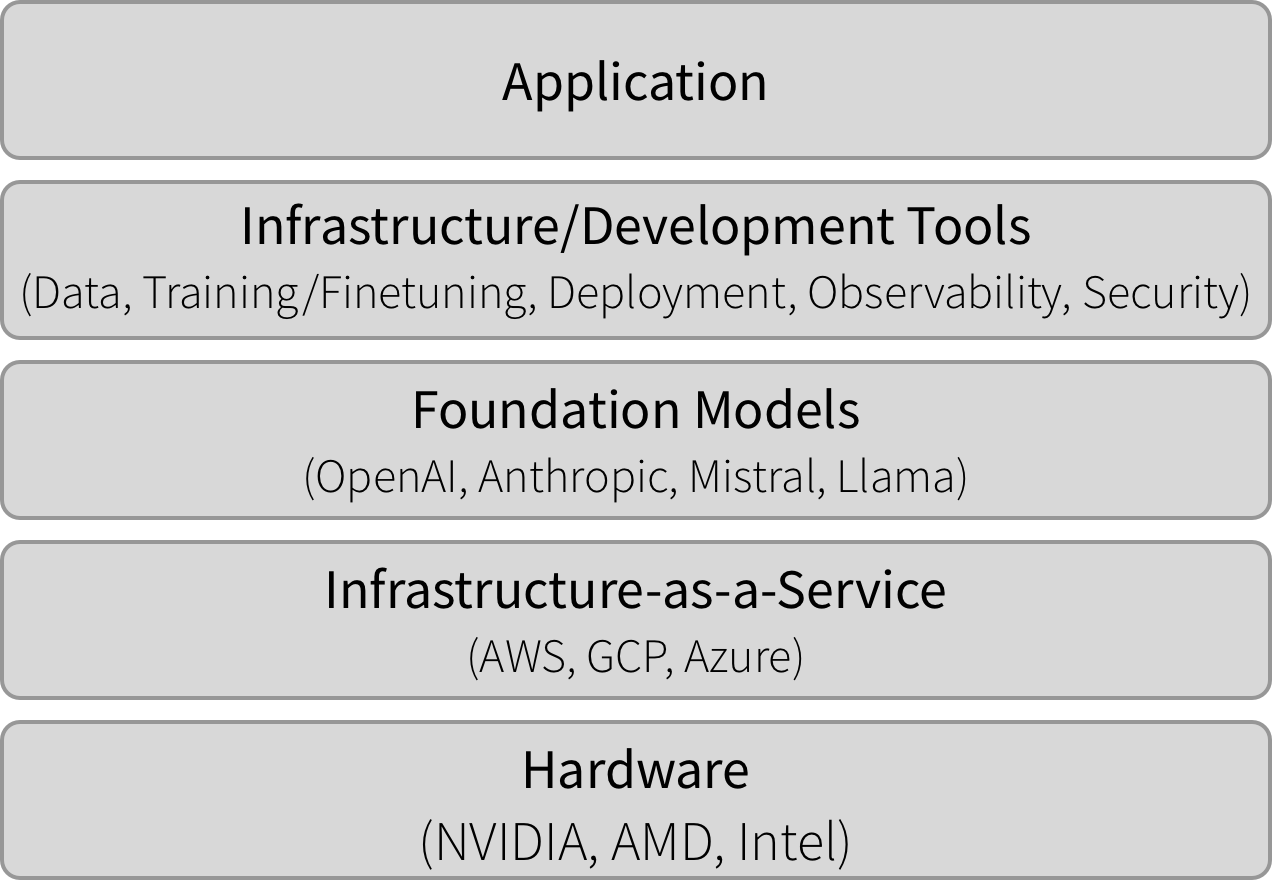
AI Stacks
In the illustration above, we can see an example cloud-based AI stack. Application developers building products such as AI travel agents, AI project management tools, or AI customer service platforms might use such a stack. In this case:
The application developer buys infrastructure software to become secure and resilient.
The application developer uses a foundation model vendor (e.g. OpenAI) via API.
The model vendor subcontracts execution to a cloud provider (e.g. Microsoft Azure).
The cloud provider purchases hardware (e.g. NVIDIA GPUs) and energy.
This scenario has a lot more “buy” than “build”.
Sometimes, companies opt for more “build” than “buy” by vertically integrating across multiple layers of the stack. For example:
OpenAI builds end-user applications, infrastructure and foundation models.
Google goes further, handling all of the above while also building hardware (TPUs).
Outside of large companies with unlimited budgets, it’s suicidal for application developers to build components internally when they’re available commercially given the cost of doing so. Acute “Not Invented Here” syndrome is a common affliction amongst strong engineering teams; many have unfortunately built their own databases, filesystems, HTTP servers, and project management tools. These companies accrue huge R&D expenses with little differentiated value if similar components are available off-the-shelf.

Given the widespread investment at every layer of the AI stack, application developers will be able to choose off-the shelf components for the majority of their stack. For example, even if a company runs models locally (e.g. on smartphones or robots) and doesn’t use the common cloud-based stack above, they’ll be part of a different ecosystem with similar relationships between applications, models, and hardware.
Follow the buck to predict where build vs. buy decisions occur
Build vs. buy decisions are the decision points that direct massive cash flows when aggregated across an entire market. Vendors that can make buy decisions go their way can achieve billions (or trillions) of dollars in enterprise value. Those that can’t, die.
If trying to build a company in a new technology market like AI, we need to identify where in the stack customers might buy something instead of building it themselves. We can play the game of “follow the buck” to trace cash flow through the value chain.
Here’s how it works:
Start at top of the stack where a customer pays for an application.
Ask: “What problems must the vendor solve to provide that value?”
For each problem, think about the vendor’s build vs. buy decision. Each decision point is a potential business opportunity.
If there’s a chance of a buy decision (exchanging money for value), goto 2 for each potential new vendor and repeat the process.
Playing this game in the real world often enough, we can make a few observations:
Companies operating at the top of the stack (application developers and business customers) make build vs. buy decisions that massively impact lower layers. Pay close attention there.
Each vendor assembles a unique “snowflake” stack for their use case.
Individual1 end users typically use products as-is without customizing the stack.
With complex stacks, such as in AI, we find there are way too many components to trace. Such stacks exhibit fractal behavior: each component contains numerous smaller components, ad nauseam. Imagine a typical application server—a physical machine, an operating system, HTTP server software, various third party frameworks and libraries, and finally the application code itself—all supported by various security and infrastructure tools. Now multiply this hundreds of times for a large-scale product with many internal services. Then add in even more third-party services accessed via API. Yikes.
Including each of these details would render a stack precisely useless. We don’t need to know about every chip2 inside a server to understand why somebody might buy it. A good stack communicates just the important bits: clear component boundaries and predictable interactions.
In systems design, encapsulating complex behavior in a single component is called “abstraction”. When the behavior of the component is predictable from the outside, it’s a “clean abstraction”. Clean abstractions are easy to understand; however, as we’ll see below, sometimes subtle interactions are not predictable from the outside leading to “leaky abstractions”.
Component boundaries signal potential build vs. buy decision points. Any time we can encapsulate a set of functionality in a component, it’s likely to be something a vendor can provide, rather than something a company must build themselves.
Technology markets are snowballs where snowflake stacks converge
A single “buy” decision doesn’t make a market. If there’s only a single buyer for a component, vendors are unlikely to build it. Only with many buyers will a market materialize to fill the void.
How do we predict where markets might emerge? If we follow the buck through enough stacks, we’ll see some patterns. Markets occur when individual “snowflake” stacks align, creating a critical mass of demand for similar components. Companies that can dominate a component across many stacks have the chance to roll up a sizable snowball of a market.
In AI, there is no universal best stack—diverse application requirements necessitate varied technology choices—however, opportunities to create snowballs exist at each layer. Components present in many stacks tend to result in one of two types of markets:
Universal components: If all users of a component have similar requirements, a unified market is likely. NVIDIA GPUs, capable of handling most AI use cases, show up in just about every stack today.
Segmented components: Divergent requirements form multiple market clusters. The AI infrastructure layer has wide variety of customer needs so it’s unlikely that a single company will dominate.
Here are a couple examples of segmented use cases in AI:
Publicly-traded enterprises deploying AI co-pilots need to prevent employees from seeing confidential financial information.3 They might want a security component that identifies confidential financial information and blocks it from being accidentally disclosed. Similar security needs show up in other enterprise AI use cases, so cybersecurity vendors have the opportunity to build a large snowball here.
A privately-held manufacturer deploying AI-powered robots may not care if their employees see financial information; however, they might instead want to predict when robots need maintenance. Many types of manufacturers will deploy factory robots, so there will similarly be an opportunity for a large snowball.
As we can see, snowballs often cluster around similar use cases and customer types.
Subtle requirements create “leaky abstractions” in stacks
How can we tell whether a component will spawn a unified or a segmented market? Staring at a stack diagram alone won’t help. Technology is not a commodity purchased by the kilogram.
Human psychology drives build vs. buy decisions; decision-makers weigh many factors to choose between purchasing, adopting open source components, or building in-house.
To correctly predict these decisions, we must think like technical decision-makers. It’s no coincidence that many founders and VCs in technical fields are engineers or could convincingly play one on TV.
In systems design, a “leaky abstraction” occurs when we need to peek inside a component to understand how it functions. In AI there will undoubtedly be leaky abstractions that cause build vs. buy decisions to deviate significantly from outside-in assumptions.
For example, consider a manufacturer automating low-volume part production. They need robots that can produce a variety of parts reliably, quickly, and most importantly, cheaply.
Assumption: With 900 current employees, they’ll buy ~300 humanoid robots if each robot working 24/7/365 can do the work of 3 humans working normal shifts.
Reality: The manufacturer instead opts for 100 traditional industrial robotic arms upgraded with AI-reprogrammability. Why?
Historically low-volume part production wasn’t automatable, hence the human labor force.
Given the size of parts, one large industrial arm produces the throughput of three humanoid robots, but at much lower cost.
The manufacturer is more comfortable buying hardware from a trusted local distributor of industrial robots vs. an unproven startup selling humanoid robots.
Leaky abstractions can make purchasing decisions go very differently than outsiders expect.
Now, consider an AI-enabled industrial robot arm vendor deciding whether to build or buy their AI foundation model.
Assumption: They’ll choose a model based on a simple cost vs. performance metric amongst many open source or commercial options.
Reality: Existing models available to them aren’t designed for real-time systems and can’t reliably handle safety curtain violations (where a human enters the work area). They’ll need to build one themselves. Alternatively, if multiple industrial robotics companies face the same issue, a new market opportunity emerges for industrial robot-specific foundation models.
Leaky abstractions can cascade down a stack, creating unexpected opportunities.
At the same time, be wary of blindly taking a contrarian stance. Outside-in assumptions often become consensus but sometimes the consensus is right. One consensus view that might be right: NVIDIA GPUs are really good and will dominate for a long time to come. For a contrarian view to be profitable, it must be both “non-consensus and right.”
In AI especially, understanding decision-maker psychology can help identify those rare opportunities where non-consensus views are also correct. It’s in these unexpected behaviors—leaky abstractions in the AI stack—where founders and investors can uncover underserved problems and develop unique insights that allow them to get a head start on the market.
Defensibility
A series of posts dedicated to answer the question: Where will value accrue in AI?
Technology markets are organized around “stacks”.
"Execution power” is becoming more important than classical “structural power”.
Market revolutions occur when “critical" technology makes a new stack “viable”.
When multiple stacks become viable in rapid succession, companies must “AND” or “OR”.
Power within the AI stack—hardware, hosting, models, and infrastructure.
Power in AI applications—big tech, switching costs, network effects, and the $100 trillion of global GDP up for grabs
I viscerally dislike the term “consumer”—feels bovine—so I try use “individual” wherever possible.
Unless you’re a semiconductor analyst predicting whom fortune will favor in a hardware refresh cycle.
“Data classification” is a hard and longstanding cybersecurity problem.